Introduction
Proxying is very useful when conducting intensive web crawling/scrapping or when you just want to hide your identity (anomization).
A convenient way to implement HTTP requests is using Pythons requests library. One of requests most popular features is simple proxying support. HTTP as a protocol has very well-defined semantics for dealing with proxies, and this contributed to the widespread deployment of HTTP proxies.
In this post I am using public proxies to randomise http requests over a number of IP addresses and using a variety of known user agent headers these requests look to have been produced by different applications and operating systems. The whole project is located on github.
TinyProxy Installation
If you wanted to use your own proxy, to avoid high delays from public proxy providers, you could install tinyproxy.
For this purpose we could also use a free EC2 instance. Just remember to enable the needed ports in the security settings.
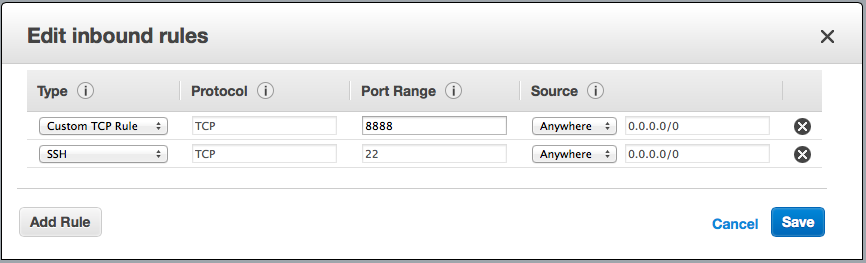
Installing tinyproxy is pretty straightforward, at least on Ubuntu. To install just type: apt-get install tinyproxy
Then configure the security settings: nano /etc/tinyproxy.conf
In the tinyproxy.conf file configure the port number (default 8888). TinyProxy does not provide authentication, it is using an allow list instead. So before closing the configuration file make sure your IP address is in the Allow list. Visit www.whatismyip.com to find your IP address. Assuming your IP address was 123.123.123.123 the line should be: Allow 123.123.123.123
You can then start to use your proxy server. To change the IP address of the EC2 instance and consequently the proxy server, simply click STOP on the server and then start it again.
Getting Started
The python code below is crawling two different public proxy websites http://proxyfor.eu/geo.php and http://free-proxy-list.net. After collecting the proxy data and filtering the slowest ones it is randomly selecting one of them to query the target url. The request timeout is configured at 30 seconds and if the proxy fails to return a response it is deleted from the application proxy list.
1 __author__ = 'pgaref'
2
3 import requests
4 from requests.exceptions import ConnectionError
5 import random
6 import os
7 import time
8 from bs4 import BeautifulSoup
9 from requests.exceptions import ReadTimeout
10
11 class RequestProxy:
12 agent_file = 'user_agents.txt'
13
14 def __init__(self, web_proxy_list=["http://54.207.114.172:3333"]):
15 self.useragents = self.load_user_agents(RequestProxy.agent_file)
16 #####
17 # Proxy format:
18 # http://<USERNAME>:<PASSWORD>@<IP-ADDR>:<PORT>
19 #####
20 self.proxy_list = web_proxy_list
21 self.proxy_list += self.proxyForEU_url_parser('http://proxyfor.eu/geo.php', 100.0)
22 self.proxy_list += self.freeProxy_url_parser('http://free-proxy-list.net')Generate Random User Agent Header
I have to mention that for each request a different agent header is used. This headers are strong in the /data/user_agents.txt file which contains around 900 different agents.
1 # load agents from file
2 def load_user_agents(self, useragentsfile):
3 """
4 useragentfile : string
5 path to text file of user agents, one per line
6 """
7 useragents = []
8 with open(useragentsfile, 'rb') as uaf:
9 for ua in uaf.readlines():
10 if ua:
11 useragents.append(ua.strip()[1:-1-1])
12 random.shuffle(useragents)
13 return useragents
14
15 def get_random_user_agent(self):
16 """
17 useragents : string array of different user agents
18 :param useragents:
19 :return random agent:
20 """
21 user_agent = random.choice(self.useragents)
22 return user_agent
23
24 def generate_random_request_headers(self):
25 headers = {
26 "Connection" : "close", # another way to cover tracks
27 "User-Agent" : self.get_random_user_agent()} # select a random user agent
28 return headersParse & Filter Public Proxies
1 # parse proxy data from url link
2 def proxyForEU_url_parser(self, web_url, speed_in_KBs=100.0):
3 curr_proxy_list = []
4 content = requests.get(web_url).content
5 soup = BeautifulSoup(content, "html.parser")
6 table = soup.find("table", attrs={"class": "proxy_list"})
7
8 # The first tr contains the field names.
9 headings = [th.get_text() for th in table.find("tr").find_all("th")]
10
11 datasets = []
12 for row in table.find_all("tr")[1:]:
13 dataset = zip(headings, (td.get_text() for td in row.find_all("td")))
14 datasets.append(dataset)
15
16 for dataset in datasets:
17 # Check Field[0] for tags and field[1] for values!
18 proxy = "http://"
19 proxy_straggler = False
20 for field in dataset:
21 # Discard slow proxies! Speed is in KB/s
22 if field[0] == 'Speed':
23 if float(field[1]) < speed_in_KBs:
24 proxy_straggler = True
25 if field[0] == 'IP':
26 proxy = proxy+field[1]+':'
27 elif field[0] == 'Port':
28 proxy = proxy+field[1]
29 # Avoid Straggler proxies
30 if not proxy_straggler:
31 curr_proxy_list.append(proxy.__str__())
32 #print "{0:<10}: {1}".format(field[0], field[1])
33 #print "ALL: ", curr_proxy_list
34 return curr_proxy_list
35
36 def freeProxy_url_parser(self, web_url):
37 curr_proxy_list = []
38 content = requests.get(web_url).content
39 soup = BeautifulSoup(content, "html.parser")
40 table = soup.find("table", attrs={"class": "display fpltable"})
41
42 # The first tr contains the field names.
43 headings = [th.get_text() for th in table.find("tr").find_all("th")]
44
45 datasets = []
46 for row in table.find_all("tr")[1:]:
47 dataset = zip(headings, (td.get_text() for td in row.find_all("td")))
48 datasets.append(dataset)
49
50 for dataset in datasets:
51 # Check Field[0] for tags and field[1] for values!
52 proxy = "http://"
53 for field in dataset:
54 if field[0] == 'IP Address':
55 proxy = proxy+field[1]+':'
56 elif field[0] == 'Port':
57 proxy = proxy+field[1]
58 curr_proxy_list.append(proxy.__str__())
59 #print "{0:<10}: {1}".format(field[0], field[1])
60 #print "ALL: ", curr_proxy_list
61 return curr_proxy_listUse Request Proxy
1 # generate a randomised request to the specific url given as argument
2 def generate_proxied_request(self, url, params={}, req_timeout=30):
3 if len(self.proxy_list) < 2:
4 self.proxy_list += self.proxyForEU_url_parser('http://proxyfor.eu/geo.php')
5
6 random.shuffle(self.proxy_list)
7 req_headers = dict(params.items() + self.generate_random_request_headers().items())
8
9 request = None
10 try:
11 rand_proxy = random.choice(self.proxy_list)
12 request = requests.get(test_url, proxies={"http": rand_proxy},
13 headers=req_headers, timeout=req_timeout)
14 except ConnectionError:
15 self.proxy_list.remove(rand_proxy)
16 print "Proxy unreachable - Removed Straggling proxy :", rand_proxy, " PL Size = ",len(self.proxy_list)
17 pass
18 except ReadTimeout:
19 self.proxy_list.remove(rand_proxy)
20 print "Read timed out - Removed Straggling proxy :", rand_proxy, " PL Size = ", len(self.proxy_list)
21 pass
22 return requestConnecting the pieces together
1 # Main method to test functionality - generating request to a local service
2 if __name__ == '__main__':
3
4 start = time.time()
5 req_proxy = RequestProxy()
6 print "Initialisation took: ", (time.time()-start)
7 print "Size : ", len(req_proxy.get_proxy_list())
8 print " ALL = ", req_proxy.get_proxy_list()
9
10 test_url = 'http://localhost:8888'
11
12
13 while 1:
14 print "here"
15
16 start = time.time()
17 request = req_proxy.generate_proxied_request(test_url)
18 print "Proxied Request Took: ", (time.time()-start), " => Status: ", request.__str__()
19 print "Proxy List Size: ", len(req_proxy.get_proxy_list())
20
21 print"-> Going to sleep.."
22 time.sleep(10)